


🌮 Newsletter #3
On parle de notre 1er micro-bootcamp, des queers dans la Tech, du stress et de listes chaînées (aka 10 minutes de lecture pour briller à ton prochain entretien d'algo) 🔗

News News News
Les 27 et 28 avril derniers a eu lieu l'inauguration du micro-bootcamp Algorithmia à Paris 🤩
La dernière semaine avant le micro-bootcamp, on peut vous dire qu’on ne faisait pas les malin·e·s. La découpeuse laser a chauffé. Les diapos se sont enchaînées. Les siestes se sont écourtées.

Mais le jour J, c’était juste le feu 🔥
En quelques mots :
- 1 week-end = 16 h de formation intensive sur le Big O, la récursion, les structures de données et quelques algorithmes célèbres 📷
- 318 slides 🖌️
- Des dizaines d'arrays en bois et de listes chaînées faits maison (passion petites ficelles 🪢)
- Plein d'exercices pour expérimenter et pratiquer 🧪
- A peu près une analogie dramaqueenesque toutes les dix minutes (comment, la récursion ne vous fait pas systématiquement penser à une descente aux enfers, vous ?) 🎭
- 16 participant·e·s INCROYABLES, qui ont bravé le réveil et co-construit une ambiance merveilleusement safe pendant tout le week-end 🔥
Et on a eu des retours bien trop cools, aussi :
 ♣ Ce qui m'a marquée, c'est la façon dont les organisatrices ont rendu l'algorithmie accessible. Grâce à une pédagogie innovante et ludique, basée sur la manipulation (merci pour les petits cubes 🔳 et le télé-achat !) et les dramas (évidemment que la récursivité ressemble à une descente aux enfers 🌪 , pourquoi n’y ai-je pas pensé plus tôt ?), les concepts complexes sont devenus clairs. ❤️ Mais ce qui a vraiment fait la différence pour moi, c'est l'ambiance inclusive et le SAFE SPACE créé par les organisatrices. Dans cet environnement, chacun.es se sentait libre d'exprimer ses idées, de poser des questions et de progresser à son rythme, sans craindre le jugement. 💜 C'était un vrai soulagement de pouvoir apprendre sans pression, dans le respect et la bienveillance. 🏋♀️ Je suis ressortie de ce micro-bootcamp avec une nouvelle confiance en mes compétences en algorithmie et l’envie d'en apprendre encore plus. Je suis reconnaissante et remplie de gratitude 🙏 envers Electronic Tales pour leur travail et pour cette expérience enrichissante. (Prochain micro-bootcamp en Algorithmie le 8 et 9 juin !)")

Autre point à noter : le micro-bootcamp s’est fait en non-mixité spontanée (pour le dire autrement, aucun gars cis n’est venu). On retient le phénomène : manifestement, quand on propose un contenu pertinent, les femmes et les personnes s’identifiant comme appartenant à un minorité de genre viennent (là où, parfois, on entend des entreprises hurler à la lune en demandant “où sont les femmes ?”).
Pour rappel, notre mode de fonctionnement par défaut est la mixité réfléchie, c’est-à-dire que, pour chaque session, on tient à garder un ratio entre les devs minorisé·e·s (femmes et personnes s’identifiant comme appartenant à un minorité de genre) et les devs alliés (hommes cis) proche des 70 % - 30 %. D’ailleurs on vend des billets selon ce ratio :

Bref, on est caliente caliente pour les prochaines sessions, et on espère pouvoir en faire plein - y compris dans d’autres villes que Paris 🚇 Mais ça, ça dépend en grande partie du bouche à oreille et de vos soutiens, donc n’hésitez pas à en parler autour de vous ☎️
Intéressé·e ?
La prochaine session en remote aura lieu les 18 et 19 mai 🧑💻
La prochaine session en présentiel aura lieu à Paris les 8 et 9 juin 🥐
Réserve ta place ici 🎟️
Modern World
Queertech
Queertech sort une grande étude autour de ce que vivent les personnes 2SLGBTQ+ dans la Tech canadienne.
L’occasion de découvrir que (surprise surprise) il est plus facile d’être blanc·he et hétéro que racisé·e et non-hétéro.
Mais aussi de mettre en lumière le gap entre ce que croient les personnes non queer (“les choses s’améliorent pour les 2SLGBTQ+”) et les personnes queer (“bif bof, Jean-Pierre”).

Stresse pas tant, là
Ami·e dev, tu te sens stressé·e ?
Cet épisode du podcast québécois Sans Filtre date d’il y a trois ans, mais il vaut le détour.
Imagine une neuroscientifique de renommée internationale qui te parle comme si tu étais sa nièce ou son neveu et que vous étiez dans sa cuisine un dimanche matin.
C’est tout simplement le meilleur contenu sur le stress et sa gestion qu’on ait entendu de notre vie. Tout ce que Sonia Lupien explique s’appuie sur des données scientifiques, et elle le fait avec un humour et un pragmatisme merveilleux.
(Si quelqu’un arrive à compter le nombre de fois où elle dit “mammouth” pendant l’émission, on veut bien la stat.)
Ancient World
Unchain my list (aka 10 minutes de lecture pour briller à ton prochain entretien d'algo) 🔗
Une chronique par Officier Azarov
Peu de choses m’angoissent plus que de voir des gens - des gens qui sont manifestement collègues entre eux - sortir pour aller déjeuner ensemble.
Imaginez : je suis là, à traîner tranquillement mon spleen à travers la ville (= en train de me chercher un sandwich), quand, soudain, un attroupement déboule d’une porte cochère (ne me remerciez pas pour la touche historique-luxe, c’est cadeau).
Tous les éléments dramatiques y sont : Jean-Michel Chef-de-projets qui a coincé Mattéo, le nouveau stagiaire, pour lui décrire semaine par semaine le plan quinquennal de la boîte ; Mehdi, qui a dit six fois qu’il avait apporté sa gamelle, mais s’est fait embrigader pareil ; Sophie, qui essaie de passer un appel urgent en même temps que Dominique continue à lui parler, parce qu’iel n’a pas calculé que Sophie avait une oreille collée au téléphone (“han, ça y est, on utilise iel pour parler des Dominique, c’est trop le wokistan cette newsletter”).
Et qui a décidé que c’était okay de reprendre le travail tout de suite après le déjeuner ? Je veux dire, à quel degré d’illusion il faut se trouver pour sincèrement croire qu’on peut digérer et conserver suffisamment de forces pour servir le capitalisme ? Genre, ton corps est littéralement en train de décomposer des aliments (qui étaient sur une étagère du Franprix il y a une heure) en nutriments indispensables à ta survie, et ton manager fait la gueule parce que tu n’es pas assez vif·vive du clic dans Excel ?
Bref, tout ça pour justifier que, l’autre jour, au lieu de faire taptap dans VS Code, mon esprit s’est lancé dans une odyssée de scroll (on a les odyssées qu’on mérite). Et voilà que, ni une ni deux, je me suis retrouvée à triturer une de mes angoisses existentielles préférées. La géopolitique mondiale ? L’état climatique actuel ? Non, bien sûr - les entretiens techniques en algo.
Évidemment, j’ai atterri sur GeeksForGeeks.

Bon, on rit on rit (comment ça, “non, pas vraiment ?”), mais la réalité, c’est que ce site est comme la station Châtelet Les Halles à Paris : ça upe, c’est encombré et c’est anxiogène, mais, que tu le veuilles ou non, tu te retrouveras forcément là à un moment ou à un autre de ta vie.
Et un des ses couloirs sur-éclairés les plus effrayants, c’est sa section “structures de données”.

Les structures de données, tu te souviens ? Mais si, ce truc dont parlait ton·ta prof le premier jour de ta formation en répétant “c’est le truc le plus important du monde”, et que les petits lutins de ta mémoire se sont empressés d’effacer. Parce qu’en vrai tu manipules juste des arrays et des objects à longueur de journées et que ta vie est très bien comme ça. JUSQU’AU MOMENT OÙ TU DOIS PASSER UN ENTRETIEN, BIEN SÛR 🥁
Oui oui, ce moment où tu vas aller fouiller sur tous les sites écrits entre l’apogée d’Avril Lavigne et la crise des subprimes pour gratter des miettes de savoir sur les listes chaînées, les stacks, les queues, les graphs et tout le tintouin, en mode “mais bien entendu que j’utilise ces structures de données au quotidien, monsieur le recruteur”.
Si tu es dans cette situation actuellement, suspends ton clic et arrête d’écumer des sites de 2002 : on va parler de la structure de données number one, celle qui va unlock toutes les autres structures de données (ou presque).
La liste chaînée.
Un peu de contexte
Reprenons du tout début. On peut diviser les structures de données en deux grandes familles : les structures linéaires et les structures non-linéaires. Parlons des structures linéaires.

Dedans, il y a les arrays (tableaux, en français), qui sont souvent les plus connues et les plus utilisées dans la vraie vie. Ensuite, il y les listes chaînées (linked lists, en anglais). Les listes chaînées, c’est la base de la base, la fondation sur laquelle on peut construire les deux autres structures linéaires qui vont nous intéresser : les stacks et les queues.
Une fois que tu as compris comment marche une liste chaînée, tu comprends comment utiliser celle-ci pour implémenter une queue ou une stack. Tu peux aussi dire dans quels cas c’est plus pertinent d’avoir recours à un array plutôt qu’à une liste chaînée pour réaliser ces implémentations. Tu comprends les enjeux de complexité algorithmique et de mémoire de chaque solution.
Bref, arrivé·e là, tu gères la fougère de la moitié des structures de données qui tombent en entretien technique.
Okay, mais j’entends d’ici le murmure timide du fond de la salle…
… C’est quoi, une liste chaînée ?
Story time 👇
Electronic tale

Fin des années 90. Après des années de dur labeur sous-rémunéré pour Word, Clippy décide de partir sur les routes découvrir le vaste monde. Il se trouve quelque part sur la côté Ouest des États-Unis lorsque la nuit tombe sur le désert. Il décide de faire du stop.

Arrive Mamie Cobol, en direct de la Microsoft Con 1996.
Le coup de foudre amical est immédiat.
Clippy et Mamie Cobol s’installent dans un coquet petit manoir.

Ensemble, iels chassent les araignées, recollent le papier peint et paient leur taxe d’habitation dans une routine sereine et heureuse… Jusqu’au jour où, un beau matin, Clippy se réveille et a une crise existentielle : qui est-il, au fond ?
Pour répondre à cette question, il entreprend de traverser le monde pour revenir dans sa ville natale.

Il va dans une première maison et pose des questions sur sa famille, qui vivait là il y a des années de ça.
Le vieil homme qui y habite lui parle de son arrière-grand-père, qu’il a un peu connu. Puis il lui conseille d’aller voir un autre voisin pour avoir plus d’informations.
Ce voisin-là lui livre aussi quelques éléments sur sa famille. Puis il lui recommande d’aller voir un autre voisin, dans une maison située dans un autre quartier de la ville.
Et ainsi de suite.

Sans le savoir, notre petit Clippy suit un pattern de liste chaînée.
Anatomie
Une liste chaînée, ce sont des nœuds (nodes, en anglais) reliés entre eux. Chaque node a deux propriétés :
value, une valeur (ça peut être n’importe quoi, par exemple “12” ou “tartiflette”)
next, une référence au prochain node
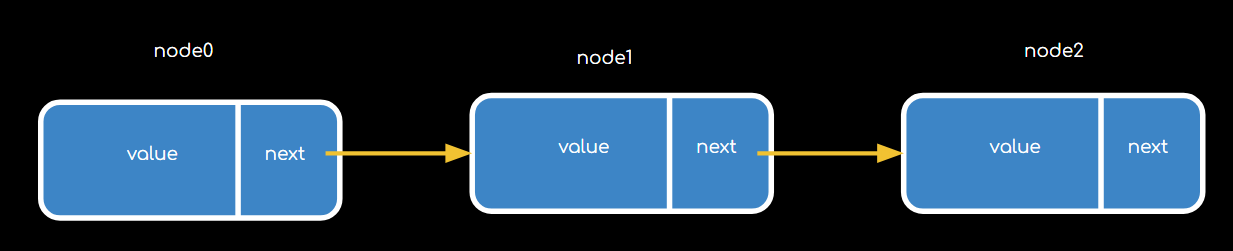
Dans l’exemple de Clippy, imagine que “value” est l’histoire que chaque voisin lui a racontée, et “next” l’adresse du prochain voisin à aller voir.
(Soit dit en passant, précisons qu’il s’agit ici d’une singly linked liste - appelée “liste simplement chaînée” en français. Il existe aussi des listes doublement chaînées, mais nous les laisserons de côté ici).
Toute liste chaînée qui se respecte a deux éléments :
Une tête (head)
Une queue (tail)

Liste chaînée VS array
Maintenant que tu vois à peu près à quoi ressemble une liste chaînée, on peut commencer à la comparer à un array pour mieux la définir.

Un array, c’est comme une machine de téléportation. Tu dis là où tu veux aller, et tu y es. On parle d’accès aléatoire (random access). En d’autres termes, que tu souhaites accéder au 1er élément d’un array ou au 200 000e, le temps sera le même.
En revanche, une liste chaînée est plutôt comme un vieux manoir avec un escalier. Tu vas devoir passer par chaque étage avant d’accéder à celui que tu veux. On parle d’accès séquentiel (sequential access). Si tu demandes le 1er élément, ça va aller très vite, mais si tu demandes le 200 000e, ça va aller nettement moins vite, car tu devras parcourir toute la liste en sautillant de next en next.
Je t’entends d’ici : “Puisque la liste est aussi mollassonne, pourquoi tu me parles de ça depuis 10 minutes ?”
Excellente question ! (Que celleux qui n’utilisent pas cette technique pour gagner du temps me jettent la pierre.)
Comme souvent en programmation, tout dépend du cas d’usage.
Si tu as besoin de stocker des données et de pouvoir accéder à telle ou telle donnée rapidement, l’array est un choix royal.
Mais imaginons que tu commercialises des chips et que tu détestes le téléphone (toute coïncidence avec des auteur·e·s de newsletter réel·le·s est totalement fortuite).
Tu décides de créer un service client où tu peux conseiller tes client·e·s sur les différentes saveurs de chips, par chat. Comme tu es tout·e seul·e à assurer le service client, tu as besoin d’une file d’attente pour que les utilisateurices patientent avant d’accéder au chat, en mode “premier·e arrivé·e, premier·e servi·e”.
Il te faut donc une structure de données qui ajoute une donnée d’un côté (quand une personne arrive dans la salle d’attente du chat) et l’enlève de l’autre (quand c’est le tour d’une personne de quitter la salle d’attente pour entrer dans le chat).
Et ça, une liste chaînée le fait très bien - mieux qu’un array, pour tout te dire.

Du code, du code, du code
Je te vois frétiller, toi là-bas.
Tu te dis que c’est bien joli, toute cette théorie, mais où est le vrai code ? Ne frétille plus, ami·e !
Niveau implémentation, en JavaScript, voici comment on pourrait traduire la notion de nodes :
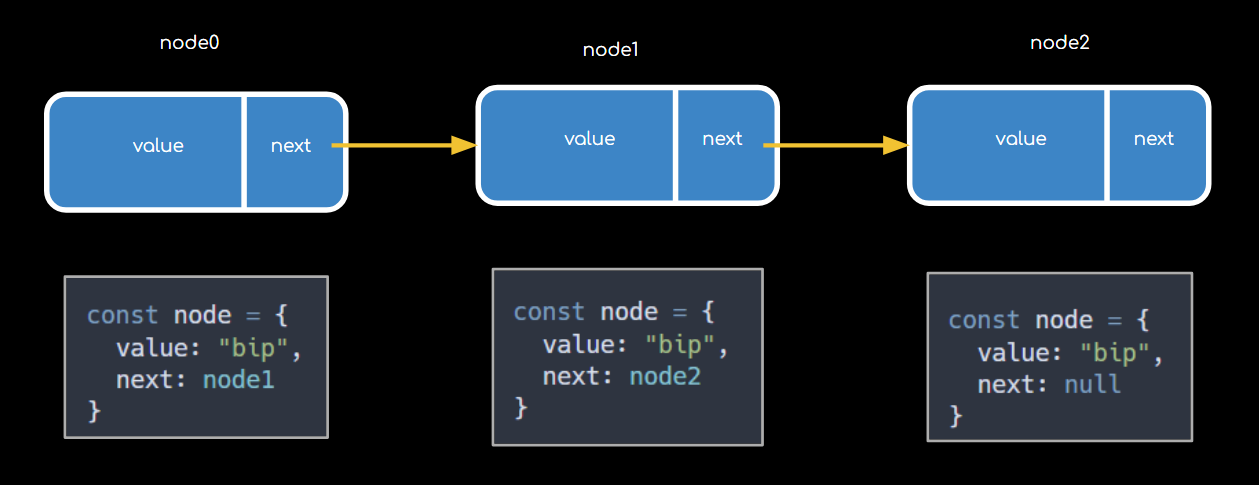
Et pour créer la liste chaînée en elle-même, on pourrait faire quelque chose comme ça :

Façon Adam (celui de la Bible, oui, pas Adam Driver) qui voit passer des bêbêtes à quatre pattes et leur donne un nom. Genre, tu es là posé·e au milieu de l’Eden, à glouper des dattes à la all you can eat, quand soudain un tas de nodes gambade devant toi, et tu décides que le node0 sera la head de ta liste, tandis que le node2 sera la tail.

Instant refactorisation : pour que notre liste chaînée soit plus facilement réutilisable, on peut l’organiser avec des classes. Une classe pour les nodes, une classe pour la liste en elle-même.

À partir de là, on va pouvoir implémenter à la mano toutes les méthodes qu’on connaît déjà avec les arrays - j’ai nommé push(), pop(), shift(), unshift() et compagnie.


Ces méthodes sont vraiment chouettes à implémenter, mais c’est une affaire dans laquelle je ne rentrerai pas dans cet article. Pour celleux que ça tracasse, voilà juste un exemple de comment on peut implémenter push(), qui permet d’ajouter un node à la liste :

Memento (linked list VS array, le retour)
Pour continuer cette visite guidée express des listes chaînées, parlons deux minutes de mémoire. Et cette fois encore, on va comparer avec les arrays.
Cette vidéo en parle en détail de façon brillante (quoique un peu complexe). Je vais simplifier au max.
En gros, quand on crée un array, c’est comme si on était un groupe d’am·i·e·s et qu’on débarquait dans une salle de cinéma en voulant absolument être assis·e·s les un·e·s à côté des autres. Ça casse les pieds des autres spectateurices et ça prend du temps.
Quand on crée un array, ce qui se passe en coulisses, c’est que notre ordinateur va aller chercher un bloc de mémoire vive contigu - c’est-à-dire un bloc de plusieurs emplacements libres situés les uns à côté des autres. Ça dépend des langages, mais, par exemple, en JavaScript, le moteur va souvent aller réserver un espace de 8 ou 16 cases dans la mémoire.

Sauf que la mémoire n’est pas vide. Elle n’a pas attendu qu’on crée un array pour stocker des données par-ci par-là. Donc trouver un bloc de mémoire contigu peut s’avérer être une opération coûteuse en termes de temps (bon, ne dramatisons pas non plus, dans les cas simples ça prend quelques millisecondes - mais les optimisations de performances se jouent souvent à quelques millisecondes, justement).
Et si la taille de l’array finit par dépasser la taille du bloc initialement alloué, l’ordinateur va devoir chercher un autre bloc, plus grand, ailleurs - ce qui, là encore, peut être coûteux.

Côté listes chaînées, on peut imaginer qu’on est toujours un groupe d’ami·e·s, mais qu’on a grandi sans développer un mode d’attachement insécure. On arrive donc dans la salle de cinéma, on constate qu’il y a déjà du monde et on décide de, chacun·e, se mettre là où il y a de la place.
Autrement dit, les nodes qui composent les listes chaînées n’ont pas besoin de blocs de mémoire contigus pour vivre : ils se casent là où il y a de la place dans la mémoire, de la même façon que les habitant·e·s de la ville natale de Clippy vivent dans des maisons éparpillées dans différents quartiers.
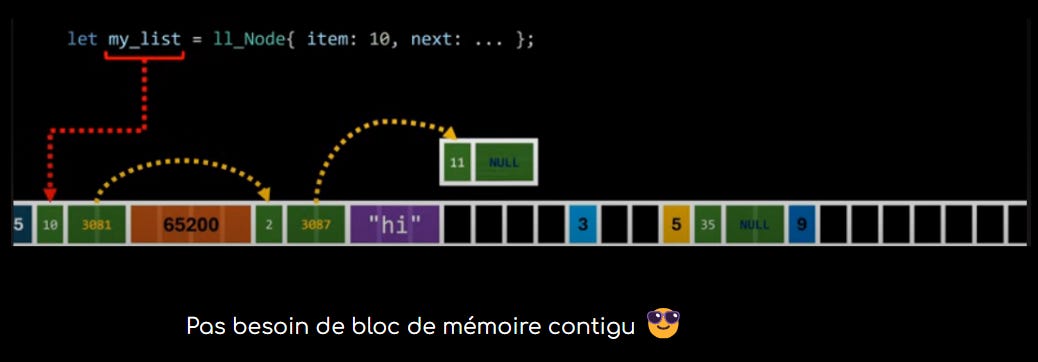
En passant, notons qu’en plus de la mémoire, il existe aussi des grosses différences entre les arrays et les listes chaînées sur le plan de la complexité algorithmique, aka du Big O - mais là encore, je ne rentrerai pas dans les détails ici.
Wrap de fin
Franchement, c’est pas un peu stylé, les listes chaînées, finalement ?
Au bout du compte, on en revient toujours à la même conclusion : GeeksForGeeks avait raison.
Bon, sauf sur le choix de sa charte de couleurs, peut-être.
Cet article t’a intéressé·e ?
Sache qu’il s’agit d’un (petit) extrait d’Algorithmia, un micro-bootcamp qui dure un week-end et qui d’adresse aux devs qui veulent progresser en algorithmique dans un espace safe et bienveillant.
La prochaine session en remote aura lieu les 18 et 19 mai 🧑💻
La prochaine session en présentiel aura lieu à Paris les 8 et 9 juin 🥐
Les places sont vendues au tarif solidaire de 75 euros ici 🎟️ (attention ça part vite !)